生成AIインデックス
RAG(検索拡張生成)
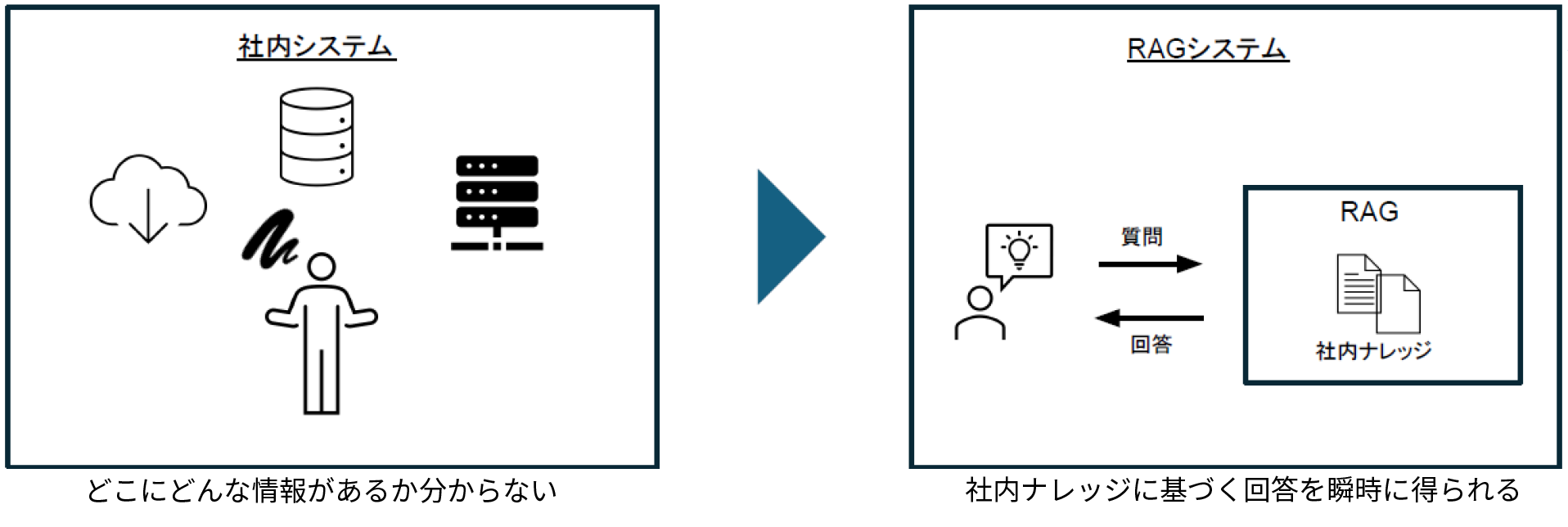
社内データの活用を目的としたRAG
(Retrieval-Augmented Generation)
RAGの回答品質向上に向けた技術検証例①
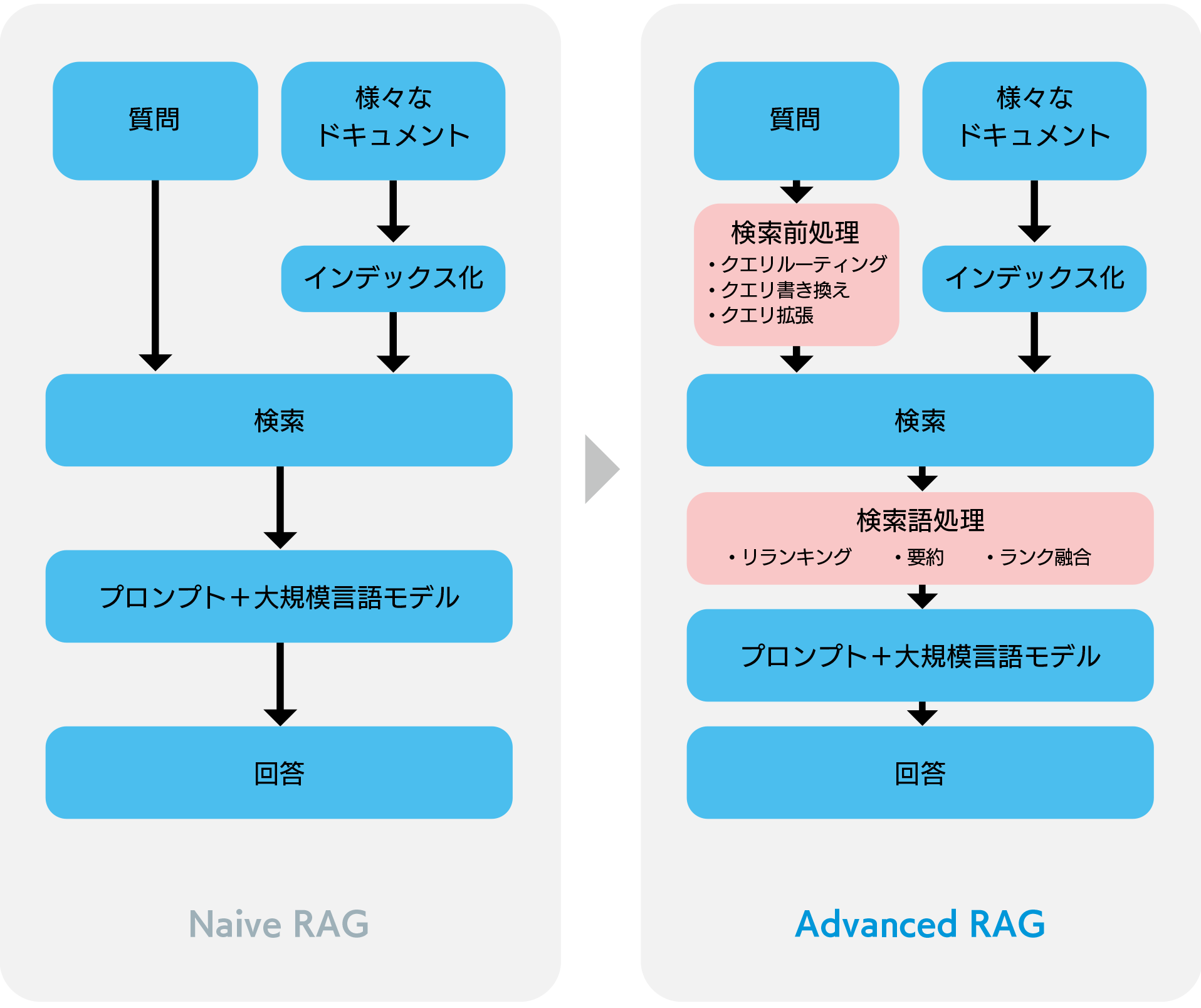
RAGの回答品質向上に向けた技術検証例②
マルチモーダル対応
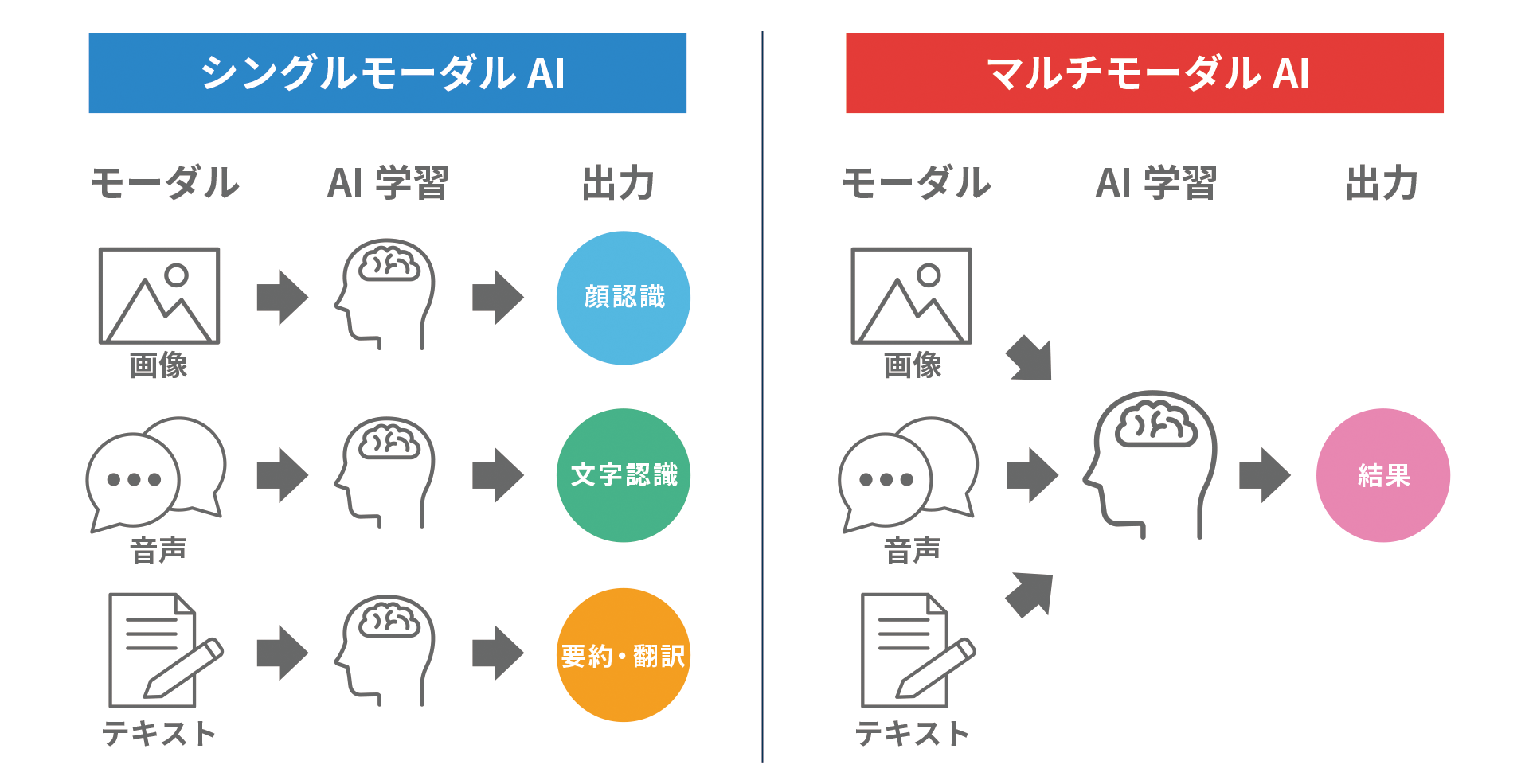
マルチモーダルな資料への対応の重要性
資料には文章だけでなく、図や表、写真などさまざまな形式の情報が含まれています。これを「マルチモーダル」と言います。
AIがこれら全てを理解できるようになると、資料の内容をより正確に把握し、活用できます。
例えば、製品マニュアルでは、文章だけでなく設計図や画像もAIが理解することで、より詳しく正確な情報提供が可能になります。
RAGが図や表に弱い理由
RAGは、テキストを元に情報を検索し、回答を生成する技術です。
しかし、図や表のような視覚情報を直接処理するのは苦手です。
これは、RAGが主にテキストベースで設計されており、数値が並んだ表などをそのまま理解するのが難しいためです。
メタデータを用いてRAGの精度を向上させる方法
AIが図や表をより正確に理解できるようにするために、「メタデータ」を活用する方法があります。
メタデータとは、図や表の内容を説明する補足情報のことです。
例えば、「この表は2023年の売上推移を示している」といった説明を付けることで、AIがより正しく解釈できるようになります。
適切なメタデータを付与することで、RAGの精度を向上させることが可能です。
- 必要な情報をしっかり探し出すこと
- 見つけた情報の中から、回答に適した部分を AI に正確に 伝えること
検索前処理(pre-retrieval)
- 検索システムを最適化(インデックス構造の改善)
- 検索キーワードの最適化(クエリの改善)
検索後処理(post-retrieval)
- 情報のランク付け(関連性が高いものを優先)
- 情報の圧縮・最適化(AIが理解しやすい形に要約)
これらの工夫により、AI(大規模言語モデル、LLM)に与える情報がより的確で簡潔になり、結果として回答の質が向上します。
プロンプトエンジニアリング最適化
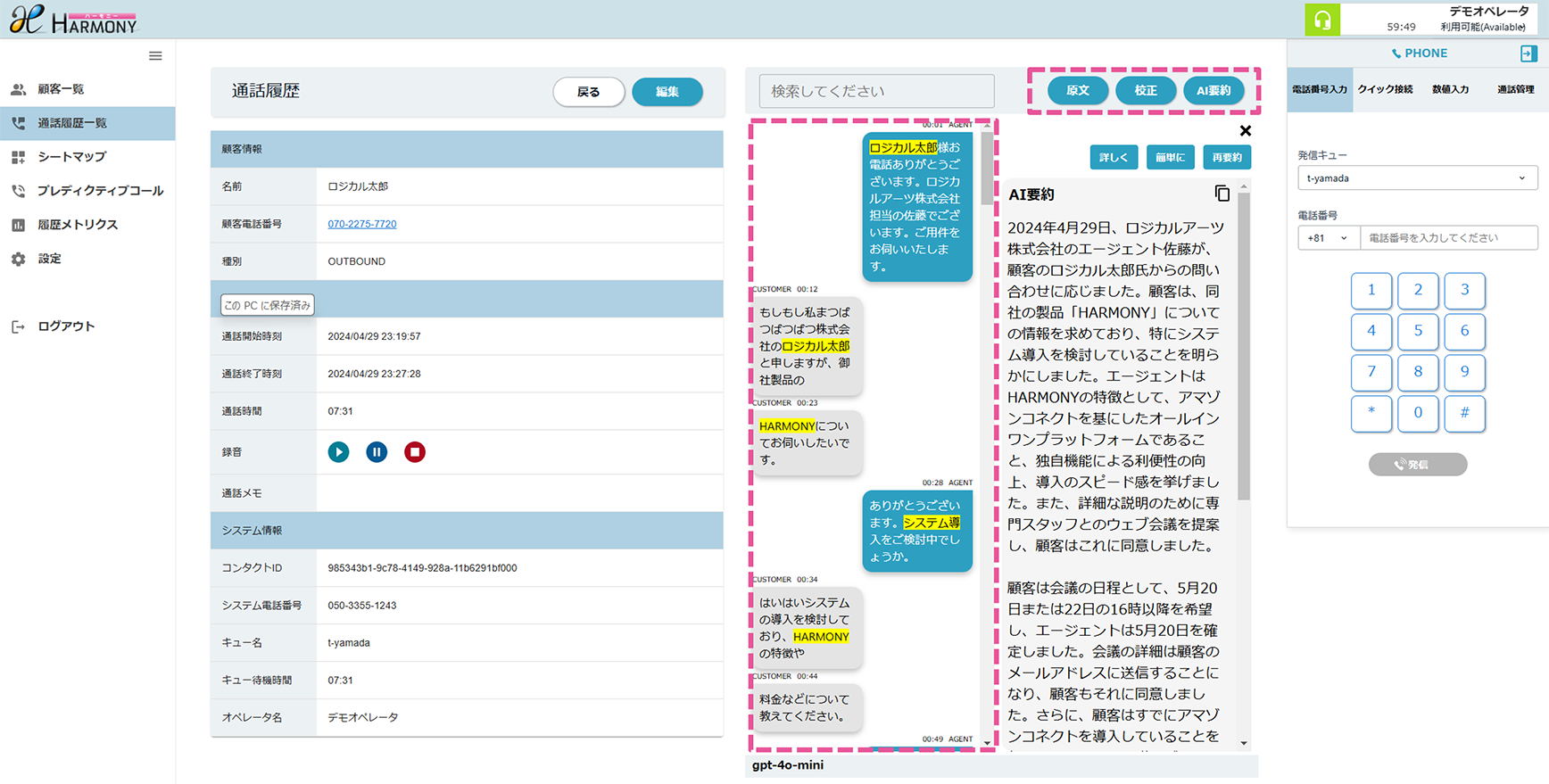
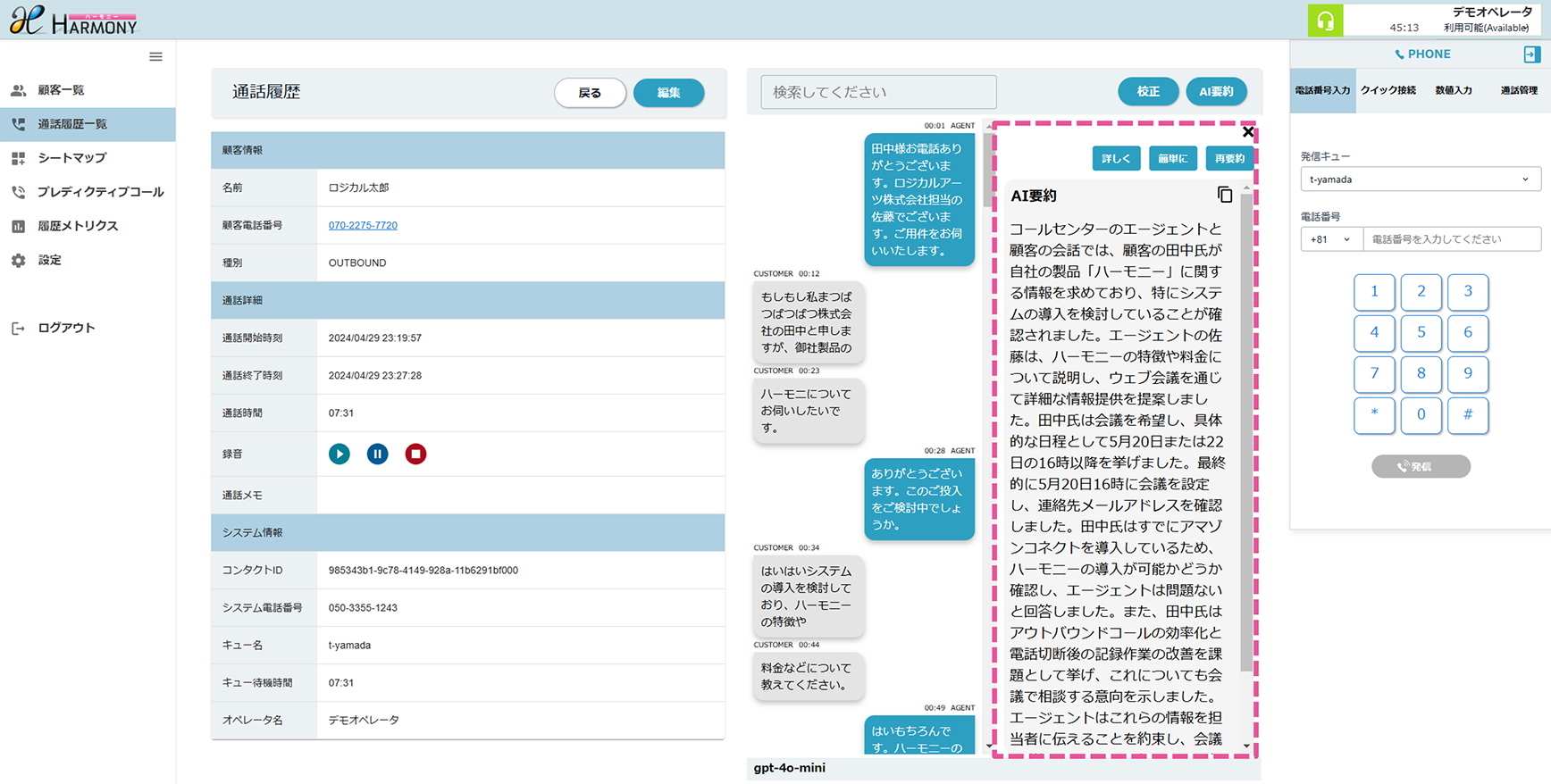
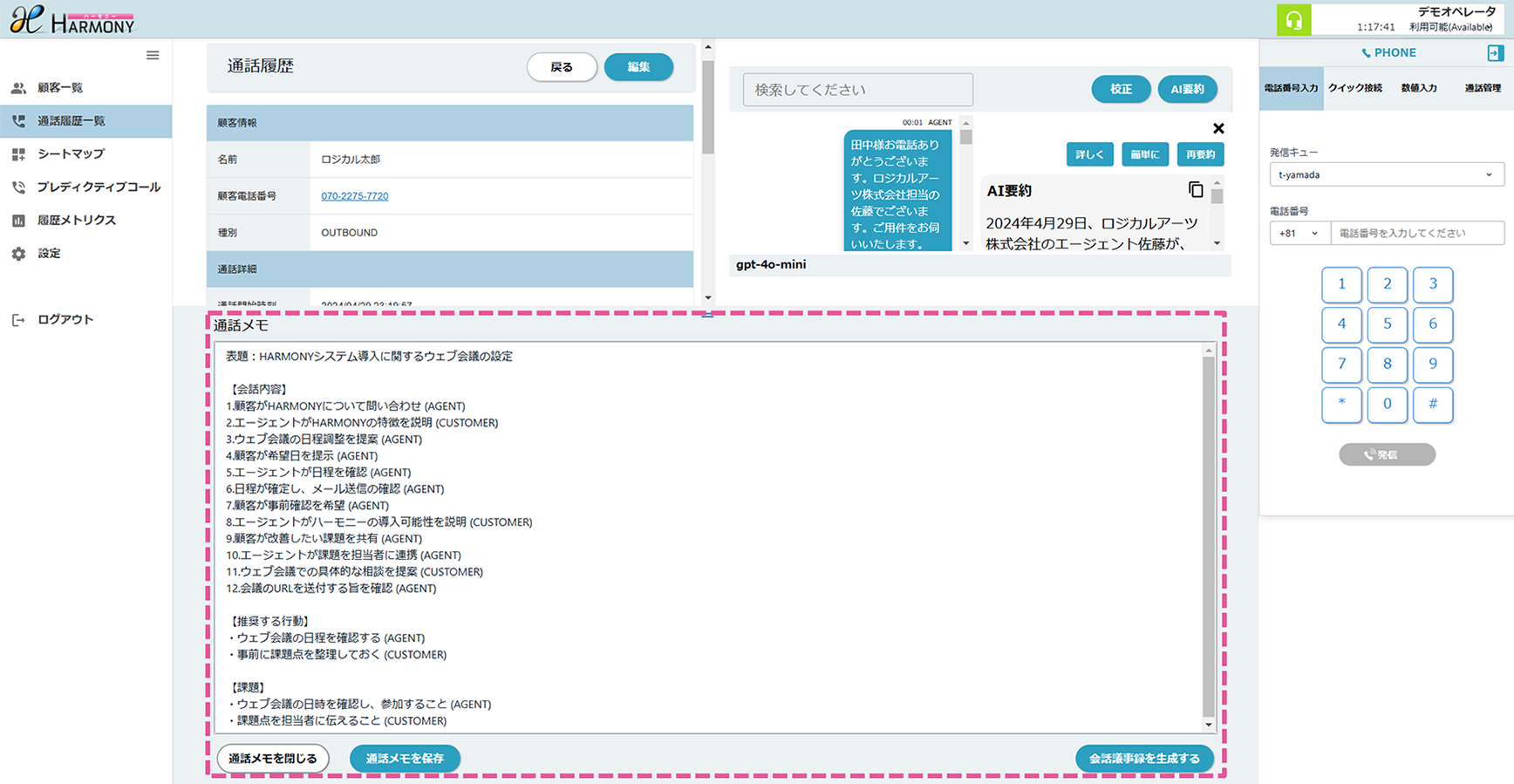
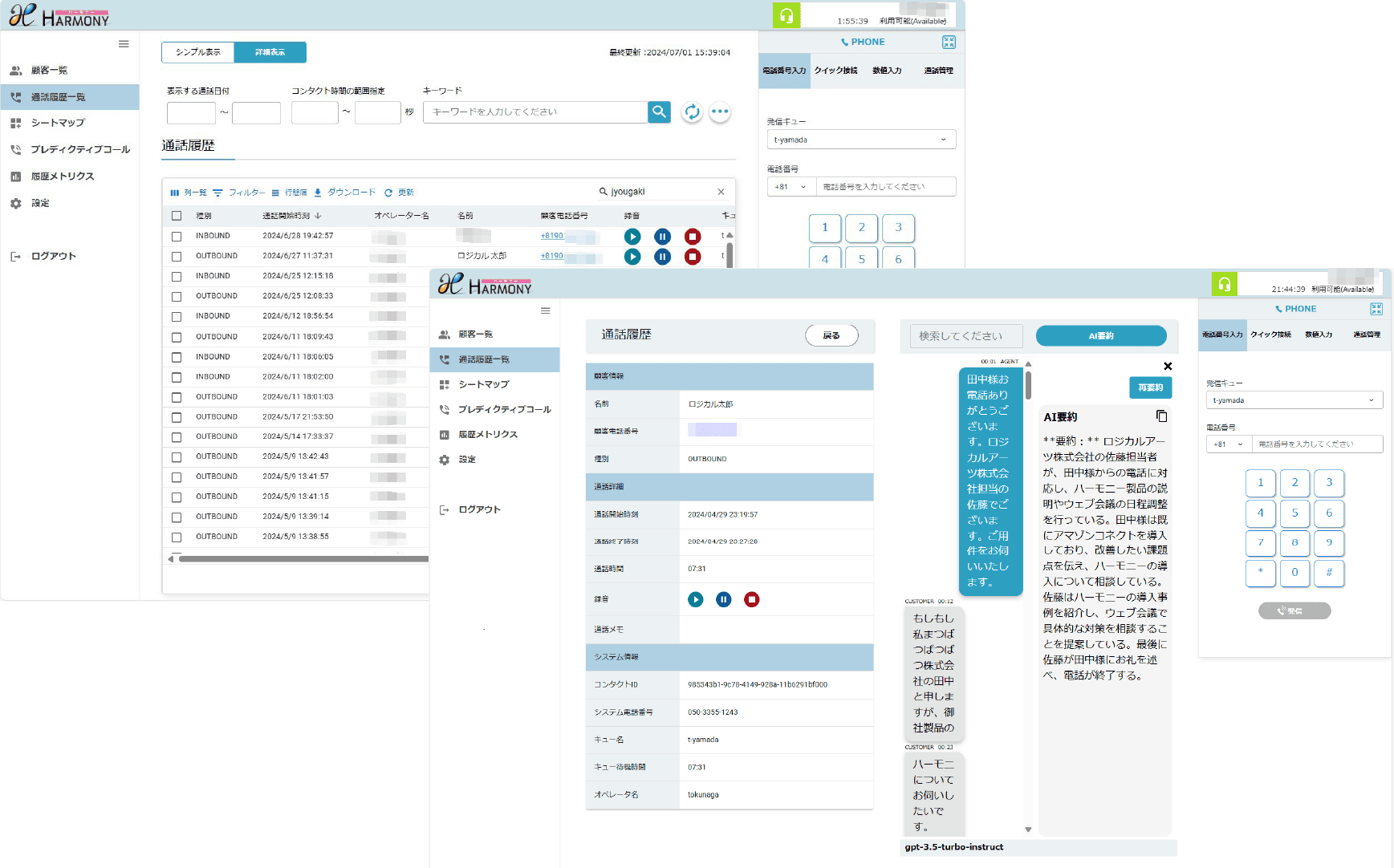
【事例1】プロンプトエンジニアリング
プロンプトエンジニアリングは、 AIに正確で有用な回答を得るために必要な指示(プロンプト)を設計する技術です。適切な質問や指示を与えることで、AIの性能を最大限に引き出し、ビジネスの課題解決や業務効率化をサポートします。この技術により、 AIをより効果的に活用できるようになります。
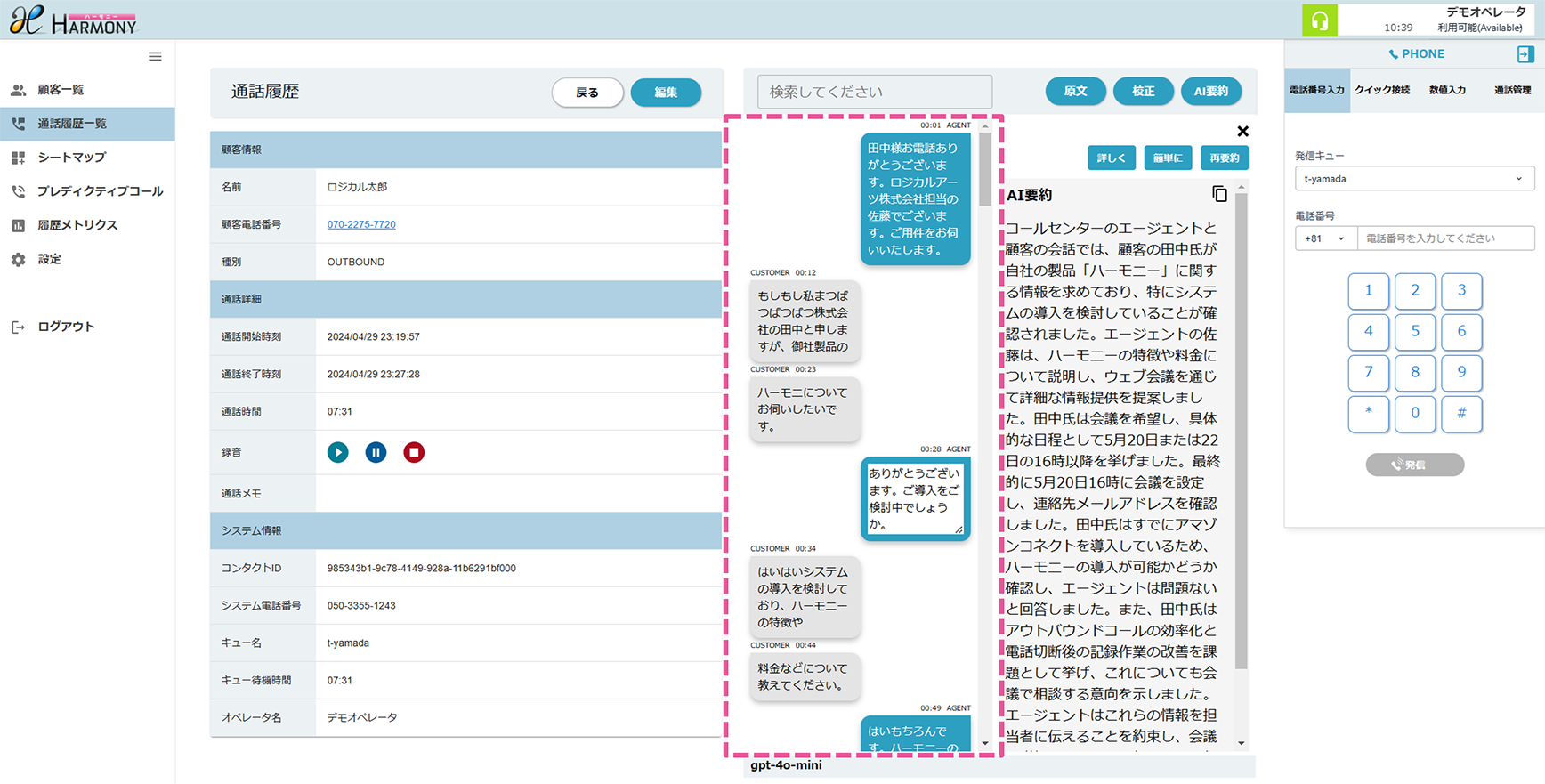
議事メモから議事録を生成した例

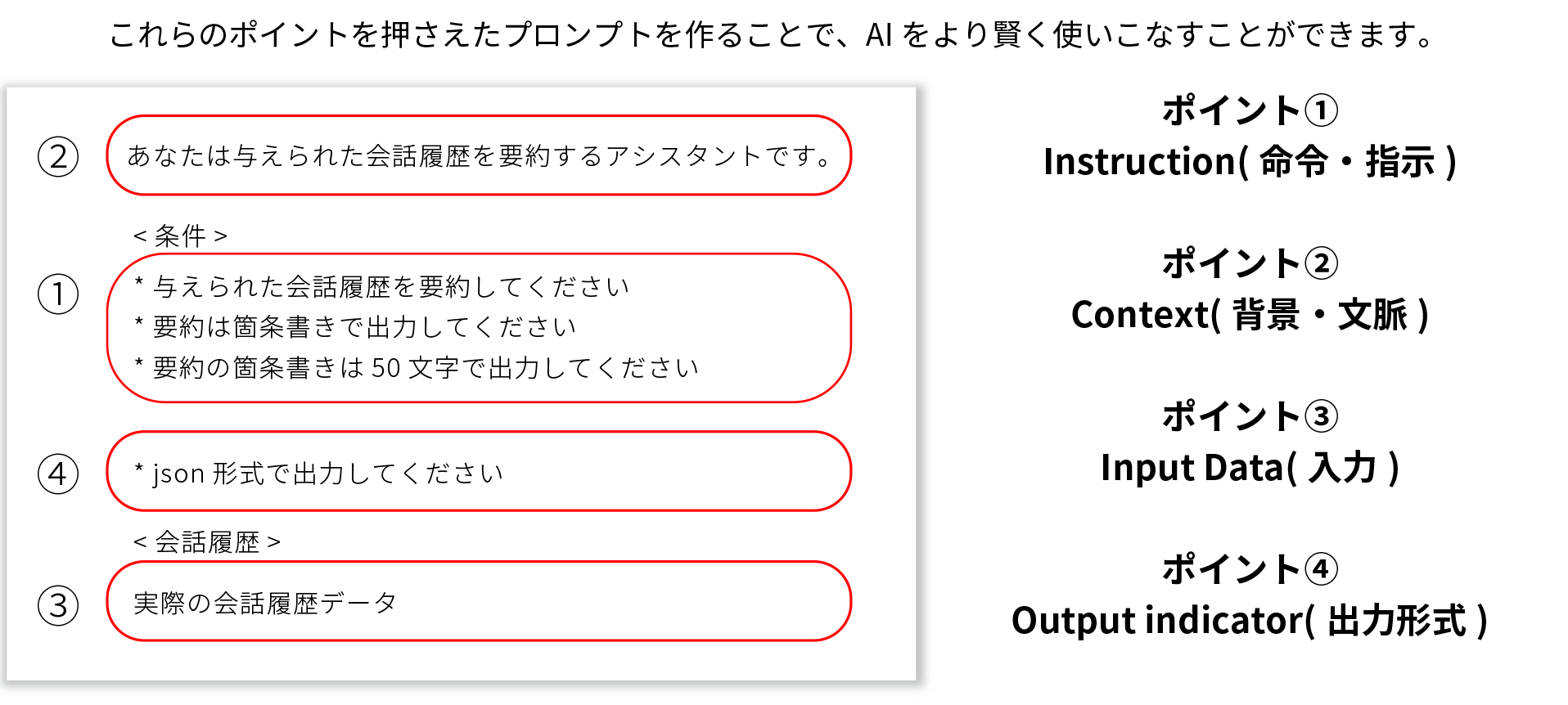
【事例1】プロンプト作成テクニックの一例
プロンプトエンジニアリングとは、AIに対してどのように質問や指示を出すかを工夫する技術です。これを上手に行うことで、AIから望んだ答えを正確に得ることができます。その基本を解説している有名な資料が「Prompt Engineering Guide」です。この資料ではプロンプト(AIへの指示)の重要な4つのポイントが紹介されています。
|
① 命令・指示 |
AIに「何をしてほしいのか」を明確に伝える部分です。シンプルで分かりやすい指示が鍵です。 |
|
② 背景・文脈 |
AIが正しい判断をするために、必要な背景情報や状況を教えることが大切です。 |
|
③ 入 力 |
AIが判断するためのデータや質問の内容そのものを入力します。 |
|
④ 出力形式 |
AIにどんな形で答えてほしいか(文章で説明してほしいのか、リストで欲しいのか)を決めます。 |
AWSを用いたRAGシステム構成例
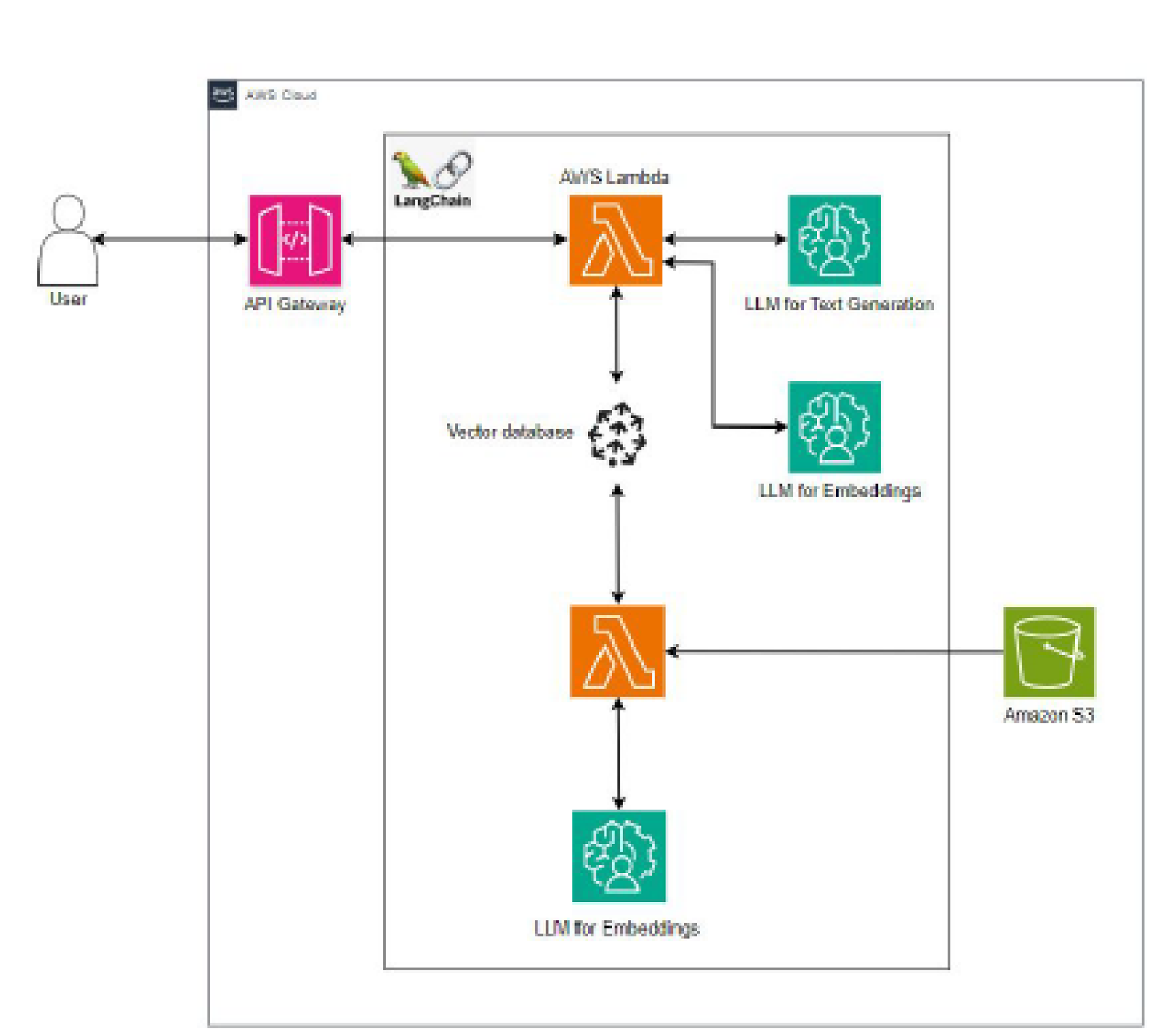
AWSに構築された生成AIを利用したRAGシステムのアーキテクチャ例です。 LangChainを使用して大規模言語モデル(LLM)と連携し、ユーザーのリクエストに応じたテキスト生成を 行う仕組みです。
-

ユーザーと
API Gateway
ユーザーはAPI Gateway 経由でシステムにアクセス リクエストを AWS Lambdaへ転送
-

AWS Lambda
(上部の処理フロー)
リクエストを処理し、 LangChain経由でLLM(大規 模言語モデル)を呼び出し リクエストに応じたテキストを生成
-
ユーザーと
API Gateway
検索精度を向上させるため、データをベクトル化 検索キーワードに対して最適な情報を検索
-

AWS Lambda
(下部の処理フロー)
ベクトルデータベースとやりとりし、検索結果を取得 RAGのためのデータを構築
-

LLM for
Embeddings
テキスト情報をベクトル形式に変換 AIがより正確に情報を活用できるようにする
-

Amazon S3
RAGに必要な社内ナレッジ や外部文書を格納するストレージ